
Enhancing traditional museum fruition: current state and emerging tendencies

As previously stated, the present paper seeks to give readers a close-up view of the following methodologies and tools currently employed to enhance traditional museums activities: 2D and 3D imaging technologies, 3D models made from 2D artwork, annotated 3D models to support metadata, watermarking, creation and virtual/augmented reality methodologies, gamification methodologies, AI for Cultural Heritage, and storytelling methodologies. For each of the strategies, the essential literature studies are presented. The overview also provides several suggestions for how to advance technology soon.
2D Imaging technologies
High-resolution images are necessary to communicate information about virtual exhibitions in virtual museums. As is common knowledge, the resolution of digital photos affects how detailed they are. Due to their dependence on available bandwidth, high-resolution photographs have recently been challenging to preserve and send over networks. Because of this, image servers adopted an imaging architecture that could offer the user scalability and options for interactivity by storing many image resolutions in a single file [5]. Even though internet connections are now faster as well as more dependable, this architecture is still in use. The Google Art Project, which was created in partnership with some of the most prominent art institutions in the world to allow anyone to discover and examine works of art online in detail, is one of the most pertinent examples of this type of architecture. Using gigapixel technology, more than 45,000 works of art have been scanned in collaboration with more than 250 institutions [6]. For art historians and curators, gigapixel photography enables precise documentation and examination of works of art. Additionally, because this form of image may be used to construct virtual representations, anybody with Internet connection can see the artwork. Visitors will be able to fully immerse themselves in the artwork, allowing them to see many subtleties that would otherwise escape their notice with their own eyes. There are very few organizations, outside Google, who specialize in getting gigapixel images of pieces of art outside of museums; this is mainly due to the technological difficulty and to the need of specialized equipment. According to [7], “some examples include the French state organization Centre de Recherche et de Restauration des Musées de France CR2MF [7], the Italian firm Haltadefinizione [8] and the Spanish Madpixel [9]”.
Apart from Google’s experience, several studies in the literature procedurally report on the acquisition of high-resolution images of paintings in museums. For monitoring, electronic recording, and display purposes, many operators employ high-resolution orthophotos of paintings. Common, undistorted digital pictures are believed to be more than enough for creating digital collections in museums, but specialized applications have more challenging resolution and dimensions requirements [10]. These two factors are crucial, especially when it comes to painting restoration and monitoring purposes [11]. A master orthophoto that will serve as the primary reference in the collecting of future multiple photos is the focal point of the typical approach. Its objective is to create a picture with a gigapixel resolution that is quantifiable (a measurement made in the image equals the equivalent measurement on the painting). These pictures are enlarged to closely match the image of the orthophoto master, like tiles in a mosaic.
The outcome is a photograph that is incredibly highly detailed, reveals the finer aspects of the artwork, and accurately captures the painting’s actual size. As a result, the success of the entire technique depends on how accurate the orthophoto is. The orthophoto is created starting with an undistorted image of the painting using metric references (points or planes), often produced by utilizing perceptual characteristics [12, 13]. The so-called “cross-ratio” method is one of the most often used techniques for analysing metrics data from images [14, 15]. This approach tries to determine the plane on which the subject (in this example, the painting) resides by using a sequence of proportions (the cross-ratio, see Eq. 1) between known points that are moved along convergent lines (with at least three points on each line).
$$\frac{{\underline{{AC}} \cdot \underline{{BD}} }}{{\underline{{BC}} \cdot \underline{{AD}} }} = \frac{{\mathop {A^{\prime}C^{\prime}}\limits_{\_} \cdot \mathop {B^{\prime}D^{\prime}}\limits_{\_} }}{{\mathop {B^{\prime}C^{\prime}}\limits_{\_} \cdot \mathop {A^{\prime}D^{\prime}}\limits_{\_} }}$$
(1)
Let consider the four positions A, B, C, and D in Eq. 1 as being aligned, with D being the point on the painting surface. On the equation’s left side, where the coordinates are defined in terms of the physical world, distances are expressed in meters; on the equation’s right side, where the coordinates are defined in terms of the image reference system, they are expressed in pixels. It is possible to A’, B’, C’, and D’ by using a correctly constructed tool that consists of a table on which a series of convergent lines with matching points are drawn, and a laser line projector. The laser line is positioned such that it is perpendicular to the desk in this last item. Then, this object is placed between the camera and the artwork so that it is entirely framed in the picture. The intersection of the “table” and the painting’s surface is highlighted by a laser line. This makes it feasible to apply the cross-ratio and proceed with the points and plane retrieval since each convergent line of the support and the painting surface can be readily located in the image. Table 2 shows a summary of the most relevant technologies related to 2D acquisition.
The use of gigapixel images (and/or orthophoto-based digital twins of artworks) is undoubtedly helpful to improve the fruition of paintings both on site and within a virtual environment. Advanced digitization techniques allow the user to enlarge images without losing resolution thus making it possible to zoom in on the works and reveal even details that are not visible to the naked eye.
Eventually, digital acquisition provides artistic creations a secure refuge. Ultra-high quality digital photographs are crucial for conservators and restorers to monitor the state of art conservation both before and after restoration, as well as to assist in the creation of conservation strategies.
Therefore, the use of this technology is nowadays spreading for enhancing the fruition of several collections like, for instance, Frescoes of Luca Signorelli in the Cathedral of Orvieto and Perugino’s selected masterpieces of the Umbrian master, including some of the most famous works in the National Gallery of Umbria as well as the celebrated Marriage of the Virgin, which is held in the Musée des Beaux-Arts of Caen, France.
3D imaging technologies and reverse engineering
The digital and/or physical 3D reconstruction of artworks for use in museums or to create virtual collections is a common idea in the scientific literature [16,17,18,19,20,21,22,23,24]. The fact that the Europeana Tech community is working on 3D digitization processes and publication pipelines is a consistent proof that the 3D digitization of cultural assets has only recently become a standard practice. The technique used in all published processes, which include 3D data collection and 3D model reconstruction, is almost the same. However, depending on the historical or artistic source, different outcomes could be expected, as stated in [17]. They are important for the long-term preservation, research, and public access to physical, intangible, and digital cultural material in the context of architectural history because they make research and presentation easier. Instead, 3D reconstruction is intended to support data collection in the broader context of cultural heritage, such as through digitization, data retrieval from database records with the transfer of knowledge, and the reconstruction, replication, and production of artifacts as well as the examination of visual humanities issues, such as a collection of intricate figurative paintings. Investigation and evaluation of sources also include three-dimensional reconstruction.
As in the case of study into the Vitruvian system of architectural orders [18], there are occasions when the emphasis is on plans and systems rather than a specific thing. Given this, archetypes are commonly derived using 3D reconstruction techniques. Such a process involves the question concerning the originality of reconstructed digital models i.e., how much the digital twin resembles the original artwork. According to [18] “the relationship between the artwork and its digital 3D representation depends on data quality assessment, visualization, historical preparation processes, conceptualization, and contextualization”.
The ability to digitize things quickly and easily with high resolution while also gathering exact surface data and distance information makes 3D imaging/scanning one of the greatest technologies for recording reality. This is particularly valid if the artwork is a sculpture, bas-relief, or building. The above-mentioned artworks may be digitally recreated thanks to 3D recording, which also makes it possible to build enormous archives of important objects. The main advantage of 3D scanning for the preservation of cultural and historical assets is the capacity to precisely recreate the dimensions and volumetric representation of scanned items.
A 3D model of a three-dimensional piece of art can be obtained in a variety of methods, as is well known. The most important methods include computer tomography, photogrammetry, laser scanning, structured light scanning, and RGB-D imaging. A method for producing 3D models from several images of an item taken from various angles is called photogrammetry [19]. In such a method, the 3D coordinates of points on an object surface are determined based on overlapping images with camera position and orientation information known as exterior orientation. The surveying industry produced the initial improvements in photogrammetry to mimic terrain [11], but this field quickly expanded to include the study of architectural sites. Agisoft Metashape, Bentley ContextCapture, and RealityCapture were the three digital photogrammetry processing software programs assessed in recent research [20], which showed their efficacy despite minor variations in overall performance. Authors in [21] provides an overview of optical 3D measuring sensors and 3D modelling approaches, together with their constraints and potentials, needs and requirements. Even if this study is old, especially considering the amazing advancements in the previous five years, these methods were cutting edge 15 years ago. However, some issues that are still a challenge in this field today were brought up in such a work: first, it is critical to choose the right methodology (i.e., sensor, hardware, and software) and data processing procedure. The right production workflow should then be designed to ensure that the finished product meets all the required technical requirements. The data processing time is required to be sped up with as much automation as is practical, but accuracy must always come first.
In Structured light, a series of structured light patterns are projected onto an item during 3D scanning; a line of illumination that is created when a narrow band of light is projected onto a surface that has been formed in three dimensions can be used to mathematically recreate the geometry of the surface from viewpoints other than the projector’s. Since it can capture a vast number of samples at once, pattern projection, which consists of many stripes at once or of arbitrary fringes, is a speedier and more flexible method. The fundamental idea behind laser scanning is the exchange of a laser signal between an emitter and a receiver, who then take in the return signal. During the receiving phase, the scanner utilizes distance-calculating algorithms to determine the kind of equipment. Several 3D scanners are in the market, typically used for industrial applications. Among them Romer Absolute Arm (Hexagon, Stockholm, Sweden), FARO ScanArm (FARO Technologies Inc., Lake Mary, USA), Minolta Vivid (Konica Minolta, Tokyo, Japan) are the most renowned professional devices. Other interesting devices, providing low-cost solutions for 3D acquisition (but also lesser resolution 3D point clouds with respect to professional 3D scanners) are the so-called RGB-D devices. Among the plethora of devices available in the market, the new Intel® RealSense™ sensors family is one of the most promising close range devices (Intel, Santa Clara, California, USA). Depth camera systems are capable of capturing millions of surface points in seconds, reporting them as raw point clouds or polygonised meshes. The trustworthiness of such systems is crucial to determine whether the acquired data meets the requirements for the specific application (fit for purpose). The specific purpose specifications are also important in defining test methods that highlights the fair strengths and weaknesses of the systems.
When the computation is based on comparing the phases of the emitted signal and the return signal, the distance between the laser’s emission and reception is calculated in terms of “time of flight” (TOF) for 3D laser scanners, or it is calculated in terms of “phase difference” (Phase shift based). Data may be acquired at speeds of up to a million points per second since the body and the mirror move quickly. Some widely known devices based on TOF and Phase Shift are produced by FARO (FARO Technologies Inc., Lake Mary, USA).
Whatever method is used, the result is a “3D points cloud of the scanned object, which can then be processed further using specialized software programs capable of reconstructing the 3D geometry of the scanned object in terms of surfaces” [21]. Accordingly, it is possible to build a 3D model of the original artwork or architectural/archaeological site. Two examples, related to previous works made by some of this paper authors, are the reconstruction of the Brancacci Chapel (Firenze, Italy) and the reconstruction of the Statue of the Penitent Magdalene (Donatello)—Museo dell’Opera del Duomo, Firenze, Italy (see Fig. 3). The Digital Humanities project Florence as It Was (http://florenceasitwas.wlu.edu), which intended to recreate the architectural and decorative look of late Medieval and early Modern structures, is another pertinent illustration. Such a project combines 3D generated representations of the artworks that were mounted inside of buildings throughout the fourteenth and fifteenth centuries with 3D point cloud models of the buildings (i.e., actual structures like chapels, churches, etc.).
Reconstruction of the Brancacci Chapel (Firenze, Italy) and the reconstruction of the Statue of the Penitent Magdalene by Donatello (Museo Opera del Duomo, Firenze, Italy) [10]
Additionally, in this work, the crucial steps outlined in the optimized workflow are based on conducting art historical research to identify the original artworks in each building, using 3D scanning (e.g., LiDAR) to obtain 3D data, using high resolution photogrammetry to capture artworks, and producing point clouds that can be further modified.
A crucial point to keep in mind when dealing with 3D acquisition of artworks is that there are frequently uncontrollable metric errors involved in the creation of three-dimensional virtual models using optical technologies when enormous objects are being reconstructed using small, high-resolution 3-D imaging devices. There are no existing options for controlling and enhancing metric accuracy, which is a major challenge within Cultural Heritage [22]. To address this problem, research is working to integrate several acquisition approaches, such as 3D range camera systems with optical tracking techniques or 3D reality-based models created from image fusion with range-based techniques.
As a final remark, it is important to highlight the relevance that 3D scanning could have in terms of students and young people’s engagement in CH. Using existing low-cost 3D collection tools (which are very user-friendly and widely available on the market), “it was possible to create an organized system of a production cycle that begins with the museum, involves the visitor, has them return to the museum, and then moves to the community”, as stated in [23]. In such a way young people and students become an active part in the process of gaining knowledge in the field, acting as “digital 3D invaders” engaged in a bottom-up system of social media (Facebook, Twitter, Instagram)-based cultural heritage enhancement. Table 3 lists tools, challenges and advantages related to the use of different 3D scanning technologies.
Another aspect to be considered is the integration of 3D models with Virtual Reality (VR) and Augmented Reality (AR). Integration into a virtual environment, such as for instance a VR Museum, is useful to provide information layers over static content, such as prints, or real-world settings, such as actual locales. Using VR headsets, desktop PCs, or mobile devices, visitors may experience an immersive and engaging way to explore your museum with 360 virtual museum tours. Because virtual reality (VR) is assisting museums in resolving two of their biggest contemporary challenges—authenticity and new museology—its function in the museum setting is becoming more and more significant. Stated differently, modern museums must: (1) offer a genuine experience; and (2) improve the experience of its users by offering edutainment, or the fusion of entertainment and education. Virtual reality (VR) helps allay these worries since it allows users to enjoyably learn about collections and view virtual pictures of objects as real [24].
The market has successfully adopted this VR method after numerous applications demonstrated its efficacy. VR headsets attracted a lot of attention in CH, as expected. These headsets operate on the principle of stereo vision and user-tracked displays, enabling richer and more immersive viewing experiences. These tools must be made available for the optional viewing mode of the Virtual Museums since they will significantly affect computer and mobile interfaces.
Companies including Oculus Rift, Sony’s Project Morpheus, HTC Valve, Vove VR, Avegant Glyph, and Razer OSVR have participated in beta testing throughout the years, and consumer versions of these devices were just recently made available on the market. Google Cardboard, Samsung Gear, and Zeiss VR One are examples of other technologies that have already developed gear and are well-known in the market. Additional wearable technologies augment and show content that combines virtual and real-world situations using small displays that are positioned in front of specialized eyeglasses. Google Glass, Microsoft Hololens, Sony Smarteyeglasses, Epson Moverio, VUZIX M100, Optivent Oral, and many other products are some of the rivals.
Some interesting examples of 3D virtual tours using Oculus Rift, are the tour of the Santa Maria della Scala Museum Complex in Siena, Italy [25] and the virtual tours developed by The British Museum, Museo del Prado, and Vatican City.
It is worth mentioning that most of these solutions are still in the beta stage and are now pricey, which prevents their mass adoption. They will develop and become accessible, just as VR headsets. In addition to these techniques, tracked 3D glasses and a tracked input device (stylus pen) offer the most complete 3D experience for this type of VR vision. Even though some of these techniques seem dated, it is feasible that they will advance because of the auto-stereo and tracked stereoscopic devices mentioned above. These techniques continue to be a crucial and practical way to distribute VR 3D material.
With AR, a user of a smartphone or tablet may point the device at a specific location and see a still scene come to life. AR technology overlays layers of virtual material on the actual world. Three qualities define augmented reality, according to [26]: (a) merging real and virtual things into reality; (b) fostering cooperation between real and virtual items; and (c) enabling real-time interaction between real and virtual objects. Thanks to these features, AR is becoming a useful tool for visitors to get more information when they view exhibitions. An important Review of methods based on this technique is in [27]. Table 4 shows tools, challenges and advantages related to the adoption in museums of different VR/AR technologies.
Summing-up, two main aspects are beneficial for traditional museums willing to implement 3D technologies. The immediate benefits of 3D scanning include virtual examination and research. The objects can be brought into the virtual workroom, and there is essentially no impact on the object’s physical integrity. According to some research, studying in museums with AR/VR support fosters higher-order thinking abilities in students, including inquiry, critical thinking, and creative thinking [28]. Visitors are more satisfied and enjoy themselves more thanks to these technologies, and wearable technology helps to customize their educational experience. Additionally, by giving students the opportunity to experience different historical situations firsthand, multisensory enhanced museum spaces can improve empathy.
Computer-based reconstruction in archaeology
The exhibition, including exhibitions in museums, onsite, or on the Web, is one of the essential activities recommended by “UNESCO, ICCROM, ICOMOS (1994)”, “for the preservation of the authenticity and integrity of archaeological excavations and finds”. This activity becomes particularly relevant when not only the 3D renderings of archaeological objects are shared and displayed but all the high-level information associated and associable with them. To this end, this section reviews computer-based methods for extracting high-level information from low-level information obtainable from discretized models of archaeological objects. Methods applied to archaeological ceramics will be considered. These findings are particularly intriguing since they are the most frequent in archaeological excavations and offer crucial details about the history, culture, and art of a location.
At this purpose, the published methods are grouped into the following groups:
Fragment features processing
Identifying semantic and morphological features on archaeological shards is essential for sharing information about human practices in various cultural contexts, such as the economy, daily life, and the material expression of religious beliefs. Typically, the archaeological potteries are handmade objects at the wheel so that they can be schematized with an axis of symmetry, the representative profile, and a set of non-axially symmetric elements such as handles, ribs, and decorations. Hence, the axis of symmetry evaluation is a fundamental preliminary activity affecting subsequent analyses. In Cultural Heritage applications considering discrete geometric models of finds, this process is complicated since it is based on the elaboration of information that is:
-
Of low-level such as the points’ coordinates and the triangles’ normal.
-
Limited in the case of fragments with small sizes.
-
Blurred by errors for handmade production at the wheel and several defects for extensive wear from weathering, encrustations, chipping, and other damage.
Based on these restrictions, published symmetry axis estimate algorithms examine several axially symmetric surface features using discrete 3D models. Recently, a few computer-based techniques have been put out to automatically assess the representative profile of ceramic sherds. Researchers have made this attempt to get beyond the standard archaeological procedures, which rely on hand-drawn sketches by archaeologists and have low reproducibility and repeatability.
Also in this case, in presence of poor and noisy information none of the methods investigated always guarantees a reliable result. The encoding of archaeologists’ knowledge in their conceptual categorization of ceramics represents a major challenge for researchers developing automatic methods for segmenting semantic and morphological features. The implementation of robust rules starting from a codebook defining the articulated knowledge is not trivial because the features to be recognized:
-
Are not associable with analytical surfaces.
-
Are generally damaged and worn, blurring their geometric properties.
These difficulties explain the few automatic algorithms available in the literature. An automatic method should first divide the axisymmetric part (ASP) from the non-axisymmetric one (NASP) and then recognize the characteristic features of each.
The automatic implementation of the dimensional features evaluation of archaeological ceramics used by archaeologists is linked to the results of feature segmentation. The results proposed by the authors in [29,30,31] show that, at the state-of-the-art, the implementation of methods that automatically assess dimensional features from the 3D model can be based on the methods developed in [32, 33]. Table 5 and Table 6 show, respectively, a comparison between different axis-based methods and the essential aspects of methods published in literature for representative profile detection.
3D Vessel reconstruction from its fragments.
Because archaeological ceramics are sometimes discovered in fragments, their assembly is valuable for investigation, categorization, and display. By examining ornamentation, technical traits, and colour through visual analysis, form, and size through the graphic depiction of the discoveries, archaeologists can identify fragments that might be from a vessel. Then archaeologists proceed with assembly within each cluster of fragments. Testing the joins, matching the sherds, and temporarily fastening the joins are all steps in the factorial operation. The shards’ surfaces are damaged by chipping and erosion, their number is unclear, and some are missing because they have been destroyed or have not yet been found, which complicates this time-consuming task [32]. In any case, these activities require a skilled operator, and since they can introduce degradation, they are avoided in the case of fragile and precious fragments. Several methods have been proposed to automatically perform the operations mentioned above in a virtual environment.
Regarding clustering, Biasotti et al. [33] “identify the essential similarity criteria used in traditional studies” and apply the concept of compatibility to comparing fragments with databases. Instead of extracting a clear answer, the authors offered the compatibility to show the significance of each piece of information to reasoning. This technique, while improving upon the state-of-the-art for automated clustering, still has certain drawbacks. For example, it cannot handle fragment similarity when the original model is absent or for small fragments.
The reassembly of an object from its fragments in the literature is called mosaicking. The more recent published computer-based methods can be classified as follows:
The analysis of the semi-automatic methods proposed by Kotoula [37], shows these methods, typically, even when based on commercial software, have limitations due to being difficult to use for non-experienced users and limited functionality in managing specific Cultural Heritage features. Table 7 lists the essential aspects of methods for archaeological ceramics automatic reassembly.
Additive manufacturing
Another key aspect to consider when creating engaging exhibitions is the possibility for 3D printing replicas that can be accessible by visitors or even used to replace original artworks, for example, when the latter is damaged or destroyed. This is possible by using additive manufacturing (AM) methods to make these replicas.
As is well known, additive manufacturing (AM), commonly known as 3D printing or Rapid Prototyping, is a computer-controlled manufacturing method that builds three-dimensional things by depositing materials, often in layers. In several technical sectors, additive manufacturing (AM) techniques such as binder jetting directed energy deposition, material extrusion, powder bed fusion, sheet lamination, vat polymerization, and wire arc have been employed [52]. Accompanied with their own standards, such methods are successfully employed for CH. The New York Metropolitan Museum of Art has significantly encouraged people to engage with its collections online. Visitors can take pictures of museum exhibits to use as the basis for their own digital models. The Met has even provided instructions for doing this in a booklet that is available online. The article points readers toward online tutorials and suggests which software to use. They also go through how to buy a 3D printer or kit or how to use a 3D printing service.
It is both great and difficult to employ 3D printing to conserve cultural treasures and relics. Due to physical deterioration, robbery, and demolition, society continues to lose priceless relics from the past. 3D printing provides a novel way to preserve these items and make them accessible to future generations. To illustrate this point, two archaeologists from the Harvard Semitic Museum recreated a ceramic lion in 2012 using 3D modelling and printing (see https://www.wired.com/2012/12/harvard-3d-printing-archaelogy/).
Three thousand years ago, during an assault on the historic Mesopotamian city of Nuzi, the original sculpture was destroyed. The fragments are kept in the museum’s collection. These were painstakingly captured from hundreds of different perspectives. A computer model was then made using the photographs. The incompleteness of the fragments resulted in certain holes in the model. They had to use entire statue scans that were also located in the same area because of this. After digitally reassembling it, they were able to produce a 3D printed replica for display.
A further example is the restoration of Iraq’s demolished Nimrud Lion (see Fig. 4) performed by Promo Design (PIN s.c.r.l., Prato, Italy).

3D printed replica of the Nimrud Lion
Additionally, accurate replicas can be constructed for exhibitions where the original work cannot be transported, as in the case of Michelangelo’s David, which will be on display at the Dubai Expo in 2021.
Finally, AM-based models of artwork can be utilized to enhance visitor engagement or for teaching objectives [53]. 3D imaging, combined with Additive Manufacturing, allows to take irreplaceable artefacts seen only in museums and “put them in the hands” of learners. Some important Museums which worked on this topic are the Smithsonian Museum and the British Museum.
Reproductions are possible for pieces that must be handled carefully. This makes it possible to examine things closely without endangering the originals. Items that are too delicate to show can be kept safely in storage while a copy is used in their place. Even replicas of damaged artefacts are possible. Before printing a “fixed” model, fragments are scanned and digitally pieced back together. These can be shown side by side in museums to give visitors a better idea of the object’s previous appearance.
Overall, AM offers various benefits for preservation over traditional manual restoration and digital archiving. Most notably, AM can create a realistic duplicate that people can “feel” by touching. Moreover, AM offers designers a fresh approach to manufacture goods that have a distinct connection to cultural history in addition to replicating artefacts. AM may contribute to bridging the “old” and the “new” and bringing the museum’s cultural heritage experience into “people’s” everyday life through these creative endeavours. Accordingly, it appears that 3D printing will play a significant role in the fields of research, documentation, preservation, and education in addition to the area of object reconstruction. Furthermore, it has the capacity to provide these applications in a way that is both inclusive and accessible.
According to [50] Of the materials currently used in AM, which include ceramics, metals and polymers, the latter are probably going to represent the biggest challenge to conservation. Tensile strength, impact resistance, and the effects of short-term curing and aging on these qualities were the primary areas of focus. For most technologies, the impacts of construction characteristics have been investigated, and anisotropy has been emphasized in several research. Given that it may eventually cause deformation, this might pose a significant conservation concern. To fully grasp the potential role anisotropy may have in the RP product deterioration, additional study is necessary.
From 2D artworks to 3D models
Most of the research in computer vision has traditionally been focused on finding 3D information in 2D pictures, photos, or paintings. It was via these research that the problem of 3D reconstruction from a single 2D picture first took form. The two pioneering works on this topic are the ones of Horry et al. [51] and in Hoiem et al. [52]. In [51] a brand-new technique that makes it simple “to create animations from a single 2D image or photo of a scene is presented”. Named TIP (Tour Into the Picture), “gives a new type of visual effect for making various animations” by means of an appositely devised user interface. The user can interactively process 2D images by adding a set of virtual vanishing points for the scene, by segmenting foreground objects from the background and to semi-automatically model the background scene and the foreground objects in a polyhedron-like form. Finally, a virtual camera can be placed in the model to animate the 3D scene. Authors in [52] proposes a fully automated approach for building a 3D model from a single image. The model is made up of multiple texture-mapped planar billboards and has the complexity of a typical children’s pop-up book image. The main discovery is that instead of attempting to restore exact geometry, researchers statistically model geometric classes based on their orientations in the image. This method divides the areas of the input image into the major groups of “ground,” “sky,” and “vertical.” These labels are then used to “cut and fold” the image into a pop-up model using a few simple assumptions. Due to the intrinsic ambiguity of the problem and the statistical nature of the method, the algorithm is not expected to work on every image. But it works remarkably well for a range of situations taken from regular people’s photo albums.
These outstanding contributions aim to construct a 3D virtual representation of the scene when elements are virtually separated from one another, along with related approaches. A more interesting technique to transition from 2D artwork to 3D models is to create digital bas-reliefs, especially if a 3D printed prototype can make the 3D information accessible to those with visual impairments. The literature features some significant works that deal with relief reconstruction from single photographs, particularly those that deal with coins and commemorative medals. To simplify the 3D reconstruction, Shape from Shading (SFS) based techniques [55] are combined with non-photorealistic rendering [53] in [54] to automatically create bas-reliefs from single photos of human faces. In [56], volume is used to convert the input image into a flat bas-relief. Typical elements of the input image include logos, stems, human faces, and figures that are projected from the backdrop of the image. These techniques can extract 3D information from 2D photographs, but their principal uses are in the development of logos, coats of arms, and numismatics. Additionally, they significantly rely on SFS techniques, which start with shaded pictures and involve 3D reconstruction using reduction strategies. Therefore, the main needed effort to ameliorate these techniques is to reduce the computational speed, as performed, for instance, in [57] where a novel method to retrieve shaded object surfaces interactively is proposed (see Fig. 5).
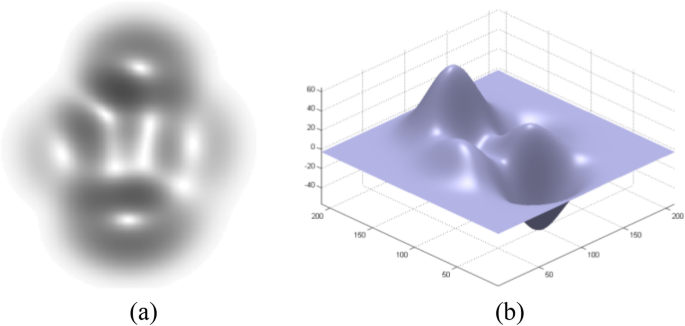
a synthetic shaded image of Matlab® peak; b retrieved surface using the approach provided in [52]
The proposed approach intends to recover the expected surface using easy-to-set boundary constraints, such that most of the human–computer interaction takes place before the surface retrieval. The method, which has been put to the test on several case studies, has potential for satisfactorily recreating scenes with both front and side illumination.
Bas-relief reconstruction features have also been integrated into commercial applications like Autodesk ArtCAM® and JDPaint.
Users may “inflate” the surface bounded by the object outlines in such software packages and employ a vector representation of the item to be rebuilt to use the software solutions. Therefore, such methods may be applied to models to produce figures that are volumetrically isolated from the backdrop while being compressed in depth, such as those produced by embossing a copper plate.
In addition, a substantial interaction is required to generate an accurate surface reconstruction; specifically, vectorizing the subject’s contours for complex structures like faces is inadequate; each component that must be inflated must be both delineated and vectorized.
Face characteristics like the lips, cheeks, nose, eyes, brows, and others must be sketched by hand. Working with paintings requires a lengthy procedure since they typically contain numerous themes that are hidden in the background (or have a backdrop that detracts from the primary subjects).
To overcome these difficulties and create models that aesthetically mimic sculptor-made bas-reliefs from paintings, several strategies have been developed so far. The most pertinent techniques are discussed in [58,59,60], where tactile bas-relief is produced using several techniques like Shape From Shading, perspective- and volume-based scene reconstruction, and rapid prototyping.
In detail, authors in [58] proposed a computer-assisted approach for producing tactile reproductions of paintings that may be utilized as a teaching aid during guided tours of museums or galleries. The approach enables” an artist to swiftly create the desired form and generate data suitable for fast prototyping machines to produce the physical touch tools, starting from high-resolution pictures of original paintings.” Laser-cut layered depth diagrams that also improve their depth relations are used to communicate the different elements of the artwork and their spatial arrangement. The best successful translation strategy for giving blind persons a correct understanding of graphical artworks is tested utilizing four various translation processes in [55] and computer-based technologies. Giorgio Morandi and Fernando Botero’s interpretations of the iconographic subject of “still life,” were selected as case studies to test the response of blind and visually impaired people (see Fig. 6).

(a) Exploration of bas-reliefs replicas of “still life” from Botero and Morandi created by researchers in [55]; (b) a zoom on the hands of the blind person during the tactile exploration of the two replicas
Using vanishing point identification, foreground from background segmentation, and scene polygonal reconstruction, authors of [56] provide a method for obtaining a 3D representation of a painted scene with single point perspective. They specifically suggested four different computer-based ways for the semi-automatic creation of haptic 3D models from RGB digital paints photos.
The findings of this study add fresh knowledge to the field of visually impaired user-oriented 3D reconstruction and make it obvious what approach must be used to create an accurate recreation of a bi-dimensional work of art.
Based on the research in [59], authors in [60] predict the location of the horizon and automatically create a rough, scaled 3D model from a single shot by identifying each image pixel as ground, vertical, or sky. They set out to provide a systematic process for the semi-automatic production of 2.5D models from paintings as their main goal. Several ad hoc techniques were used to solve many of the basic problems that come up when dealing with artistic representation of a situation.
To produce a reliable reconstruction of the scene and of the subjects/objects envisioned by the artist in a painting, these systematic methodologies concentrate on an interactive computer-based modelling procedure that includes the following tasks:
- 1)
Preliminary image processing-based operation on the digital image of a painting. This phase mainly focuses on segmenting the scene’s objects and fixing image distortion. To create a high-resolution image that keeps shading since this information is to be used for virtual model reconstruction, a digital copy of the source image to be reconstructed as bas-relief is generated using the suitable image capture method and lighting. The different elements of the scene, such as the people, clothes, buildings, and other elements, are appropriately identified after the image has been recorded. This process, known as “segmentation,” can be finished using any of the methods outlined in the literature [55].
- 2)
Perspective geometry-based scene reconstruction. To organize the segments of the beginning picture into a coherent 2.5D scene, it is important to define the attributes of the areas after segmentation. This is so that the subject representing the scene may be positioned in the space geometrically and consistently while still being characterized in terms of flat regions, which is required by the volumetric information retrieval approach created. In the literature, there are several techniques for creating 3D models from perspective scenes that have shown to be quite successful in resolving this problem (see, for example, [58]). Most of them, and in particular the technique described in [59], may be employed effectively to complete this task. This type of spatial reconstruction may be carried out by using [59] findings in conjunction with the layered depth diagrams created using the approach outlined in [58]. In contrast to similar approaches in the literature, the proposed method may be able to model oblique planes, which are planes represented by trapezoids whose vanishing lines do not converge in the vanishing point. The process begins by creating an RCS (Reference Coordinate System). The “vanishing point coordinates on the image plane \(V=\)(\({x}_{V}{, y}_{V}\)) are computed thus allowing the definition of the horizon \({l}_{h}\) and the vertical line through V, called \({l}_{v}\)”. After finding the vanishing point, the x, y, and z axes are placed on the image plane, perpendicular to the horizon (pointing right), perpendicular to the image plane (according to the right-hand rule), and perpendicular to the image plane, respectively, to create the RCS. The origin is taken in the bottom left corner of the image plane. Thus, while seeing a simple perspective-painted landscape, the following 4 types of planes may be identified: Vertical planes perpendicular to the image plane and whose normal is parallel to the x axis; oblique planes, all other planes not included in the perspective view; horizontal planes perpendicular to the image plane and whose normal is parallel to the y axis (among them, it is possible to define the “main plane” corresponding to the ground or floor of the virtual 2.5D scene). After the planes have been located and assigned to one of the categories, a virtual flat-layered model may be constructed by giving each plane a suitable height map. The foreground, or the virtual scene element closest to the observer, is represented by a white value while the backdrop, or z = 0, is represented by a black value. Since the main plane should, in principle, extend from the foreground to the horizon line, a gradient that is represented by a linear graded ramp that runs between two grey levels was used to generate the main plane’s grayscale depiction: “the level \({G}_{0}\) corresponding to the nearest point \({p}_{0}\) of the plane in the scene (with reference to an observer) and the level \({G}_{1}\) corresponding to the farthermost point \({p}_{1}\). Consequently, to the generic point \(p\in [{p}_{0},{p}_{1}]\) of the main plane is assigned the gray value \(G\) given by the following relationship” [54]:
$$G = {G}_{0}+\left(\left|p-{p}_{0}\right|\cdot {S}_{grad}\right)$$
(2)
where \({S}_{grad}= \frac{{G}_{0} }{\left|{p}_{0}-V\right|}\) is the slope of the linear ramp.
- 3)
Volume reconstruction. Once the height map of the scene and the space distribution of the depicted figures have been set up, the volume of each painted subject must be determined for the observer to discern its genuine quasi-three-dimensional shape. As was previously said, to achieve this goal, it is needed to transform all the information gleaned from the painting into shape details. First, a straightforward user-guided image processing-based approach is used to recreate any objects in the picture that resemble primitive geometry. The final projected geometry may be assigned to a simple form like a cylinder or sphere. The user is requested to select the clusters using a GUI. Each selected cluster thus stands for a single blob (i.e., a region with constant pixel values), making it simple to compute the geometrical properties of each cluster, such as its centroid, major and minor axis lengths, perimeter, and area. It is easy to distinguish between a shape that is approximately circular (i.e., a shape that must be reconstructed in the form of a sphere) and an approximate rectangular (i.e., a shape that must be reconstructed in the form of a cylinder) based on such values using well-known geometric relationships used in blob analysis. The cluster is uniformly subjected to a gradient after being identified as a certain shape item. If an object is only partially visible in the scene, it must be manually classified by the user. The user must then choose at least two points that define the primary axis of cylinders, while for spheres, he must choose two points that roughly define the diameter and a point that is roughly in the centre of the circle. The greyscale gradient is automatically computed once these inputs are given.
The response given by a panel of end users demonstrated the technology’s ability in generating models reproducing, using a tactile language, works of art that are often completely inaccessible [60].
The technique was used to create a 2.5D replica (tactile bas-relief) of Masolino da Panicale’s “The Healing of the Cripple and the Raising of Tabitha” painting in the Brancacci Chapel of the Church of Santa Maria del Carmine in Florence, Italy (see Fig. 7). The reconstruction is mostly carried out utilizing SFS-based methods, with reference to topics that are not repeatable using simple geometries (such as Tabitha). This specific decision was made because, to accurately depict on the flat surface of the canvas the various grayscales of the real form under scene illumination, the artist often creates the three-dimensional illusion of a subject using the chiaroscuro technique. This raises the hypothesis that the only significant information that can be used to reconstruct the volume of a painted figure in a painting is the brightness of each individual pixel. The performance of most techniques used on real-world photographs is currently insufficient, while SFS approaches demonstrate to be effective for extracting 3D information (for instance, a height map) for synthetic photos (i.e., images made starting from a predefined normal map). Additionally, since paintings are handmade works of art, many details of the scene that are depicted (such as the silhouette and tones) cannot be perfectly replicated in the image. Additionally, painters commonly paint diffused light since it is difficult to predict the direction of the light and because imagined surfaces are not always completely diffusive.

Masolino da Panicale’s “The Healing of the Cripple and the Raising of Tabitha” painting was recreated in bas-relief and may be found in Florence, Italy’s Brancacci Chapel of the Santa Maria del Carmine church. [56]
The SFS problem’s solution in relation to real-world photographs becomes much more challenging because of these limitations. For these reasons, the current research suggests a streamlined method in which the height map \({Z}_{final}\) of all the subjects in the image is created by combining three separate height maps: (1) “rough shape” \({Z}_{rough}\); (2) “main shape” \({Z}_{main}\) and (3) “fine details shape” \({Z}_{detail}\):
$${Z}_{final}={\lambda }_{rough}{Z}_{rough}+{\lambda }_{main}{Z}_{main}+{\lambda }_{detail}{Z}_{detail}$$
(3)
It must be remembered that since the eventual answer is created by adding together various contributions, several simplifying hypotheses that are true for obtaining each height map can be presented for each of them.
The developed method was also widely disseminated among specialists working in the field of cultural heritage, with special mention for specialists from the Musei Civici Fiorentini (Florence Civic Museums, Italy) and from Villa la Quiete (Florence, Italy), as well as the Italian Union of Blind and Visually Impaired People in Florence (Italy).
According to their recommendations, authors created a variety of bas-reliefs of well-known works of art from the Italian Renaissance, including “The Annunciation” by Beato Angelico (see Fig. 8) on display at the Museo di San Marco (Firenze, Italy), some figures from the “Mystical marriage of Saint Catherine” by Ridolfo del Ghirlandaio (see Fig. 9), and the “Madonna with Child and Angels”.

Prototype of “The Annunciation” of Beato Angelico placed in the upper floor of the San Marco Museum (Firenze), next to the original Fresco [56]

Prototype created for “Madonna with Child and Angels” by Niccol Gerini that resembles the Maddalena and the Child figures taken from the “Mystical marriage of Saint Catherine” by Ridolfo del Ghirlandaio [56]
Main findings in the field of 2.5 models’ retrieval from paintings are listed in Table 8.
As mentioned above, the main aim of 2.5 reconstruction starting from paintings is to help Museums in manufacturing several bas-reliefs resembling a painted scene to help blind people to access inherently bi-dimensional works of art. The reviewed methods allow a semi-automatic reconstruction of a painted scene and drafts several methodologies to create a digital bas-relief, to be eventually manufactured using AM technologies.
Table 9. shows main solutions arising from 2.5D reconstruction starting from painted images.
Watermarking
In the CH world, access to digital contents that resemble artworks is tightly related to copyright protection. According to [61], the management of the generated 3D models’ digital rights has come under scrutiny as three-dimensional modelling and digitalization methods are used more frequently in cultural heritage field. Therefore, even though the issue of digital rights management protecting data from theft and misuse has previously been addressed for a variety of other information types (software code, digital 2D images, audio, and video files), there is a need to develop technological solutions specifically devoted to protecting interactive 3D graphics content.
A true innovation in this field may be “the adoption of digital watermarking to link copyright information on the newly proposed type of cultural data (visible and invisible annotated 3D representations of artworks), as it enables the rapid exchange of crucial information to promote access to and sharing of European cultural knowledge” [62]. The development of new geometric data processing technologies is particularly beneficial for 3D watermarking technology since geometric data includes inherent curvature, topology, and no implicit ordering (regarding the normal sampling of an image). However, 3D watermarking introduces a brand-new class of issues that were not present in the image and video situations. As a result, it is not a straightforward 2D to 3D extension. In terms of picture and video media type, a 3D model may also be subject to more intricate and sophisticated attacks. Therefore, adapting conventional image and video watermarking algorithms to this novel type of media is quite challenging. As a result, only a small number of algorithms to conceal sensitive information (for IPR, authentication, and other purposes) within a 3D model have been established, even though many strategies and methods to embed copyright information in images and videos have been developed and tested with good results.
Transparency, robustness, and capacity are the primary requirements of a generic watermarking system, according to the academic literature [63]. The first one means that “the original image shouldn’t be harmed by the inserted watermark.” The capacity of the watermark to respond to different attacks, whether unintentional (such as cropping, compression, or scaling) or intentional (i.e., intended to destroy the watermark), is known as robustness. “Capacity is the maximum amount of data that can be stored in digital data to guarantee accurate watermark recovery” [64].
Due to the distinctive features of each form of data, “specific algorithms and implementations had to be created. Audio, video, stereoscopic video, pictures, and 3D data have all been carefully examined in literature” [64, 65].
Artificial intelligence in the CH field
Several daily services, such as online shopping and streaming of music and video, employ artificial intelligence (AI). In museums, artificial intelligence has been applied in several applications, both visible to visitors and hidden from view.
Indeed, according to the EU Briefing PE 747.120—April 2023 [66], AI has unexpectedly entered the CH scene with both promising and surprising applications, including the ability to reconstruct works of art, finish a great musician’s unfinished composition, identify the author of an ancient text, and provide architectural details for potential architectural reconstructions.
Within AI, Computer Vision (CV) is an enabling technology, since it is a powerful artificial sense to extract information from images: about places, objects, people, etc. It is possible to use it to automatically understand both contextual behaviours and situational conditions of people to provide the right information at the right time and place, e.g., to improve user interactions in museums. Regarding this, in [67] has been presented a system that performs artwork recognition and gesture recognition using computer vision, allowing an interaction between visitors and artworks in an exhibition (see Fig. 10).
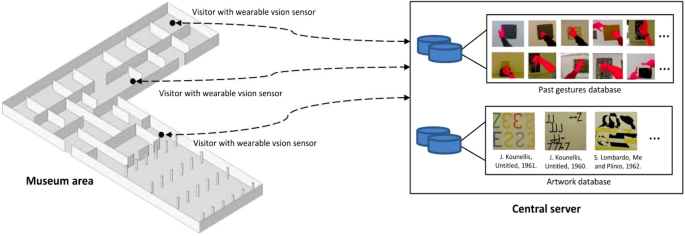
Scheme of the system presented in [63]: users have a wearable system that provides an ego-vision video stream processed by a central server that recognizes gestures and framed artworks
A CV system based on neural networks for artwork recognition on mobile devices has been proposed in [68], as shown in Fig. 11; the goal is to implement a smart audio guide that, using also machine learning techniques for audio event recognition and user movement, is able to engage with the user when it is more appropriate, e.g. when he’s paying attention to an artwork and not when he is moving around or participating in a conversation.
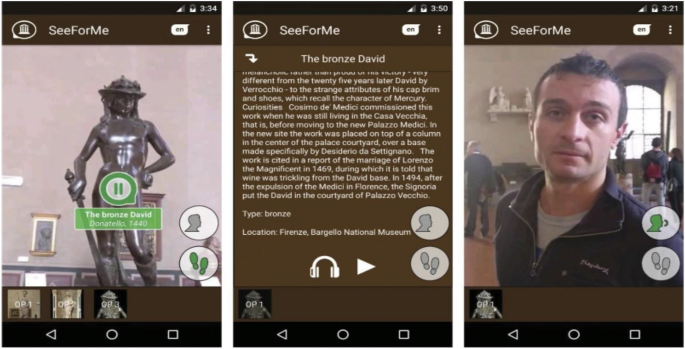
Examples of interfaces of the system presented in [64]. On the left, the user is listening to the description of the artwork; on the centre, the user is reviewing an item in the history; on the right the user is speaking with someone not focusing on any artwork
CV can help to manage digital collections, considering both high-quality archive materials and images from web and social media.
Convolutional neural networks have been proposed in [69] to recognize artworks in collections of heterogeneous image sources. More recently multimodal neural networks like CLIP have improved the results in this context [70], adding zero-shot capabilities.
Generative AI models have been used to restore missing parts of the “Night Watch” painting by Rembrandt [71], or to perform inpainting of damaged areas (automatically detected through segmentation) as in [72]. AI can be used also to revamp and restore iconographic materials such as postcards and videos of historical archives. Deep neural networks have been proposed for colorization and restoration of B/W photos [73], and to restore and colorize films using a deep neural network [74], eliminating scratches exploiting temporal coherence of neighbouring frames (see Fig. 12). A method to recover videos of damaged analogic archives has been represented in [75].

Example of restoration of old films using the method proposed in [70]; Top row shows the input, bottom row the results of the restoration
AI and Computer Vision can help to improve the planning of an exhibition, evaluating how visitors interact with it; this technology can be applied also to cultural sites. In [76] the authors have shown that tools for facial expression recognition can be successfully used as alternatives to self-administered questionnaires for the measurement of customer satisfaction, evaluating this approach in a heritage site using a commercial tool (see Fig. 13).
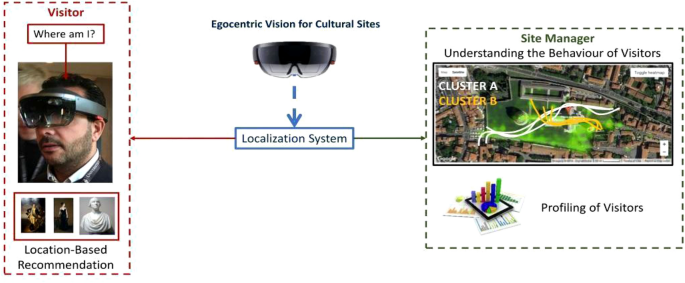
Diagram of a system presented in [73] which uses egocentric visitor localization to aid the user and augment his visit (left) and to provide useful information to the site manager (right)
The authors of [77] take into account the issue of localizing visitors in a cultural site from egocentric (first-person) images, i.e., obtained from a wearable device; the theory is that “localization information can be useful both to assist the user during his visit (by suggesting where to go and what to see next, for example) and to provide behavioural information to the manager of the cultural site” (e.g., how much time has been spent by visitors at a given location? What has been liked most?). The authors have released a dataset that can help future researchers in the field, as well as the AI models used to recognize the locations of the site. It is interesting to note that one of the devices used to capture the images of the dataset is a Microsoft HoloLens, which can be used also for A/R applications. The dataset has been expanded to include object recognition and retrieval tasks in [78].
The Menmosyne system (see Fig. 14) placed at the Bargello Museum in Florence [78, 79] employed visitor observation through cameras, tracking of their movements within a museum hall, and how long they spent viewing an artwork to create a list of the artworks that each visitor would be interested in seeing. Then, using user re-identification, these favourite artworks are utilized to give tailored information and targeted recommendations of other items of interest on an interactive table.

From the studies reviewed above, it is evident that AI is considerably changing the audience engagement, both inside and outside a museum’s four walls. Although the public is drawn to visually appealing AI applications when they engage with visitors, the technology can be even more useful when used in museum operations. Several technologies employ artificial intelligence (AI) to make choices and enhance museums for both staff and visitors, including websites, chatbots, and analytics tools. How significant technologies are adapted to institutions’ public purposes and maintain their worth in the public domain is a crucial concern for both the Museums developing them and the technologies themselves. AI has a lot to offer, but it should be ensured that there are issues related to moral obligations and the rights of audiences to be uphold.
Gamification
Gamification, which is the application of game design features beyond the typical environment of games, has emerged as one of the key methods for socializing and enhanced communication with people in several fields, including cultural heritage. In this situation, computer vision approaches can aid in boosting user engagement [80, 81]. In the learning and education fields, gamification is growing in relevance, in view of the high effectiveness of ‘learning by doing’: students can be immersed in complex scenarios that are not representable in easier ways. Thanks to gamification, it is also possible to improve the students’ problem-solving ability, to stimulate cooperation exploiting tools they are already familiar with, and to enhance long-term memory thanks to recurring references in the game. The paradigms, and relative tools, included in the platform, will greatly help to develop story led interpretations, allow scalability to more artwork, lowering the burden on the platform user, i.e., the creative side, and eventually foster the production of significant engaging materials in a relatively short time.
In fact, gamification has been implemented at several museums worldwide. Just to cite a few, Petrosains Museum, located in Kuala Lumpur, Malaysia, carried out early experiences in developing systems for engaging stories about the science and technology of the petroleum business. The Nintendo DS Louvre Guide, which features a GPS and 3D images especially for the museum, was developed in 2012 by Nintendo and the Louvre. More than “700 photographs, 30 + hours of audio commentary, high-resolution images, 3D models, and video commentary” were included in the guide.
Visitors are requested to mimic a sculpture’s position through the “Strike a pose” application created for the ArtLens Exhibition [82], and they receive feedback on how accurately they did so. Visitors had the option of sharing their positions, seeing others’ poses, and trying out new stances. The site user is instructed to mimic a sculpture’s unusual attitude after viewing a photograph of it. To determine how successfully the visitor captured the sculpture’s stance, a Kinect sensor assesses how closely their pose resembles the original and calculates a percentage. The percentage achieved increases with improved matches. The skeleton matching software measures how well each sculpture matches the poses of museum visitors using a library of human-generated skeleton data obtained using Kinect data. Visitors can view other visitors’ photos, attempt a different stance, and send their own image capture [83] (see Fig. 15).

Example of “Strike a pose” use [79]
Instead, the “Make a Face” app focuses on faces, matching visitors’ expressions with a piece of art from the museum’s collection using facial recognition and landmark detection. Visitors see a portrait to determine the sentiment of the subject before matching their facial expression to another image. Facial recognition software instantly correlates a visitor’s facial expression with pieces of art in the CMA’s collection. The system records the visitor’s expression while measuring the nodal points on the face, the separation between the eyes, the contour of the cheekbones, and other recognizable traits. Then, to identify a match, these nodal points are set up against the nodal points computed from a database of 189 artwork images. The matching faces are gathered into strips in the form of a photo booth, and these strips are subsequently exhibited on the Beacon close to the gallery’s entrance. Additionally, the user has the option of emailing their “photo strip” to oneself and sharing it with others [83], as depicted in Fig. 16. Given the difficulty in implementing such approaches on mobile devices at the time of their creation, the “Strike a pose” and “Make a face” applications are both available as installs.

Example of “Make a Face” used in [79]
Despite the two aforementioned methods do not provide a reward to the user, they are based on a social activity that not only stimulates the user’s interest in the artistic work, but also conveys the message to acquaintances and friends who may be intrigued firstly by the app and, more importantly, secondly by the work itself.
Gamification can lead to short-term motivation, but it may not last long. User-centred design, which states that “a game has to give experiences of competence, autonomy and relatedness to the players, [83]” must be incorporated into the design process. These components of game design ought to make sense to the user and influence players’ perceptions in a favourable way. These components need to be connected to an event or an activity. Research indicates that the platform(s) utilized to include viewers in serious games should be user-friendly and participatory. Higher degrees of cognitive involvement are a result of both elements. When utilizing the platform, visitors’ cognitive engagement increases, which improves learning outcomes and their overall visit happiness. As a result, there is a greater chance that guests will visit the communications museum again. These outcomes support the gamification platform’s implementation in the telecom museum. For this reason, it seems like a potential effort that might be expanded upon and modified for use in different types of museums or establishments that preserve cultural material.
Language as a tool for enhancing artworks fruition
As already mentioned, GLAM actors require new techniques and modern technologies to deploy and disseminate the amount of knowledge found in cultural material. With reference to digitized items, these must be able to tell a story to be valorised. This means that museums must be able to deliver insightful, detailed, and didactic content to both general and specialized audiences by providing content that can pique the interest of an increasingly digital audience and raise awareness of the patrimony of cultural institutions worldwide.
Most literature in this context share the idea that digital storytelling is the key approach to engage the visitors [84,85,86]. Digital storytelling, implying a creative use of digital (meta)data, and “narrative metadata” (specific descriptors related to the possible employment in specific scenarios), is a powerful tool to develop engaging “encounters” which satisfy these prospects (depending on the target audiences, the developed “encounters” will be customized for specific backgrounds and expectations). In many areas, what was formerly largely an authoritative voice addressing the public through publications and exhibition displays has drastically changed into a multifaceted experience that encourages engagement and conversation with visitors.
This holds true for both traditional and Virtual Museums (VM), if not more so. A VM is a digital entity that combines elements of a physical museum to enhance, augment, or supplement the museum experience. Virtual museums retain the authoritative status granted by the International Council of Museums (ICOM) in its definition of a museum, and they can function as the digital equivalent of a physical museum or as autonomous entities [87]. Like a traditional (physical) museum, a VM can be built around particular artifacts, like in an art museum or a museum of natural history, or it might be made up of online displays made from primary or secondary materials, like in a scientific museum. Additionally, a VM may be defined as a typical museum’s mobile or online services (e.g., exhibiting digital replicas of its collections or exhibitions). To create an engaging experience within a VM, digital storytelling is required to build multimedia strategies to involve new audiences without alienating regular visitors; therefore, this has been a direct reaction to a more diversified audience. With storytelling, museum curator will be able to build interactive and engaging experiences without worrying about technical or presentation issues, allowing them to focus on content creation.
From a technical point of view, digital storytelling requires several ICT-based components:
-
an authoring platform i.e., a web application where professional users will find the necessary tools to create scenes, arrange the story narrative through these scenes, include content and setting the transitions between them.
-
A set of tools for managing different kinds of objects and services such as annotated 3D models, 2D content, videos, maps, avatars, etc.).
-
A WYSIWYG (“What you see is what you get”) visual scene editor with a set of properties to configure its behaviour and look, like position, size, event listener, source and much more, depending on the characteristics of the artwork.
-
A database where information is stored (content repository).
-
A set of graphical user interfaces and/or devices for human–machine interaction.
While all these technical tools are easily implementable (even if a huge work is required to create the contents), interestingly only a few literature methods consider linguistic or language-based tools and methods [90]. Consequently, only a few works deal with the implementation of linguistic tools in museums and/or exhibitions.
From a more linguistic point of view, in an Italian context, the locution “virtual museum” was introduced around the 1980s, and is a polysemous expression that has taken on, over the years, “an increasingly elusive meaning, especially due to the considerable changes in the scenario produced by the continuous technological transformations of communication and information” [88].
This terminology refers first to “the virtual reconstruction (navigable or not, immersive or not) of a monument or a more or less extensive site” [89] which can be used on site to improve and implement the museum itinerary in terms of both reading and interpretation of the work and, more generally, of the narrative that one wants to convey within the museum.
Examples include the Domus Aurea, the ancient house of the Roman emperor Nero, of which only a small part located on the Colle Oppio, in the city of Rome, is still accessible to tourists. Placed inside the Parco Archeologico del Colosseo (https://colosseo.it/area/domus-aurea/), the Domus, thanks to the use of innovative multimedia technologies and interventions (e.g., video mapping, immersive reality, projections, virtual reality installations), can now be virtually visited by the user in almost its entirety. In this specific case, the creation of a virtual museum offers a cognitive and emotional contribution, corroborating the storytelling of the archaeological route through the virtual reconstruction of the historical site.
In this case there is no need for virtual or physical reconstruction of artworks, since the reproduced works are actually visible in physical museums (a different case would be if the virtual museum were to compensate for the loss or destruction of an object or an archaeological site), but there is however the function “of enabling the reading and interpretation of the works […]; a compromise that could be useful as a preparatory (or post-paratory) to viewing the real work, especially in the very frequent case where the museum hosting it lacks adequate tools for such functions” [91]. Again, storytelling plays a significant role in this situation; one may choose to employ a variety of narrative techniques to convey the history of the new museum rather than just arranging the pieces according to importance or chronological order. Instead, one could create educational and enjoyable pathways for the visitor. An example of such a virtual museum comes from the Italian marketing agency “Digital to Asia”, which, together with the Italian production company “Way Experience”, created a virtual museum containing the works of Leonardo da Vinci. The museum has been made available on the Chinese platform “Alipay”.
The concept of “website accompanied by the physical museum” is another definition of “virtual museum”. It is typically regarded as “a web site that shows all or a substantial part of the exhibition of the real museum, with more or less rich complements concerning the works and collections” [91]. The visitor can use such a museum type for one of two purposes: either to explore the museum in person or virtually while they are there (see, for example, https://www.museoegizio.it/scopri/tour-virtuali/), or to conduct research in the collection database (see, for example, https://collezioni.museoegizio.it). If the first objective is chosen, the virtual museum can support the narrative of the museum by providing access to relevant multimedia material.
Whatever the type of museum (traditional or virtual), it seems clear that storytelling, is one of the main tools that the museum must adopt to engage the visitor. For storytelling to be effective, further consideration must be given to the language utilized, in addition to the creative design of the museum route and all elements of the exhibition and setting. Accordingly, the exhibition panels and captions serve as the gold standard for evaluating the level of care devoted to language in museums. However, at present, this textual typology has not been sufficiently considered by linguistic studies, not least because the drafting of captions and panels has often been entrusted in the first instance to museum experts, some writers and communication experts. In other words, the involvement of the linguist is almost always missing. The language used in captions and panels is frequently assessed; however, from a textual and linguistic standpoint, this sort of material is frequently inconsistent. Exhibition panels frequently make use of specialized terminology (without explanatory notes) and present complexity in sentence structure (subordination is used more), and a lack of information hierarchy, just to mention a few lacks in textual and linguistic terms. Further efforts are therefore required to improve these aspects.
Source link


